

Postcards from the Future started as part of the process of creating a new class on the future of business models for the University of Michigan Center for Entrepreneurship, and is now where I spend time thinking about how the new generation of AI will change how we live and do business.

I’ve been seeing a lot of chatter on social media and other places about the “stochastic nature of AI,” and thought it’d be worthwhile to take some time to work through some of my thoughts on this subject.
First of all, by “AI,” folks are (and, for this post, I am) referring to foundational Large Language Models. LLMs like ChatGPT, LLAMA, etc. And, by stochastic, people are referring to the fact that these systems exhibit variation between responses to identical prompts.
To illustrate, here are two responses to the identical prompts, generated back to back, by the University of Michigan’s U-M GPT (based on OpenAI’s GPT4-turbo model):

Which one is the best answer? How do I tell? How does the ChatBot decide what to write? Why does this matter?
In both my outside work and through the class I teach at the Center for Entrepreneurship, I have had many conversations with founders who aspire to be part of this next wave of AI-enabled commercial solutions. The conversation inevitably touches on three things:
Data: What data are you using to augment the foundational model? Why is that the right data? and do you really have freedom to use that data for a commercial solution?
Model: Which foundational model are you using, and why?
Variability: How do you manage the variability in the results generated by the LLM?
Why Should I Care?
As a long time enterprise software wonk, this variability in outputs of LLMs has given me pause when it comes to their commercial application. Outside of purely creative endeavors, of course. Anything relating to text, image, sound generation is a slam dunk, no-brainer for this technology.
To be very clear, I’m very optimistic about the applicability of LLMs in a wide variety of solution domains. But, I get shivers when I imagine Enterprise Software CEO Kurt walking into a former customer like Daimler, Boeing, or Dow and saying “you can use our software to make the best possible [X] you can make, and, by the way, this solution will generate different answers every time, even for identical inputs. And, best yet, I don’t know why!”

Users expect consistent results from their information systems. In other words, they want deterministic solutions managing their information. There should be one “best” answer for the optimal throughput of a specific process at a specific time. One right answer for the strongest possible bracket geometry for a specific material and mass. One right answer for the optimal inventory to hold for a given SKU in specified market conditions. One minimum cost for a given bill of materials.
So, if LLMs are stochastic, doesn’t that potentially significantly limit the kinds of problems they can be applied to?
Jumping ahead, the answers are no, and no, but humor me for a minute.
But, are LLMs Really Stochastic?
Perhaps being a bit too pedantic here (there’s a surprise), but neural networks simply are not stochastic systems. Neural networks consist of nodes with connections and weights that translate an input into an output. They run on digital hardware that translates binary signals into other binary signals, in fixed ways, based on a defined set of instructions. Given a starting condition and fixed set of inputs, the output will always be the same. Sure, statistical methods are often used in the training of neural networks, for example to avoid false minima, over-fitting, and other challenges of optimization, but, once the network is trained, the same input means the same output every time.
Unless …
Unless the networks are explicitly of the type Stochastic Neural Networks, (Boltzman Machines, for example) but modern LLMs aren’t those.
Or, unless the computations done by the model are hitting the representational limit of the hardware.
Sidebar: Computation at the Physical Limits of Hardware - Material Removal Simulation circa 1990
A long time ago, I was tasked with building a material removal simulation product for a company that had a sophisticated graphical programming and simulation solution for manufacturing robots. Basically, the idea was to be able to put a simulated tool on the end of a simulated robot arm (or machine tool), put a virtual block of material in a simulated vice, and watch the block change into a finished part as the tool runs G-code (a CNC machining program) over it. Really cool, cutting edge stuff, especially back in 1990.
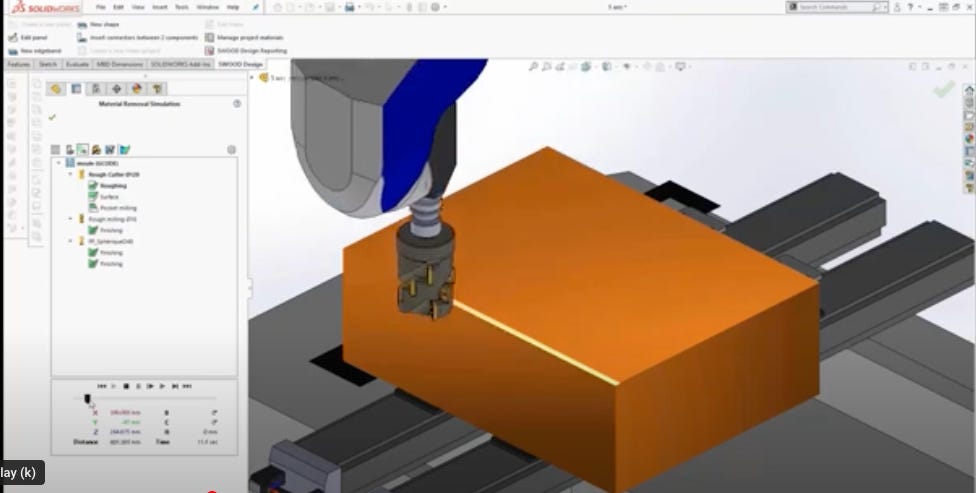
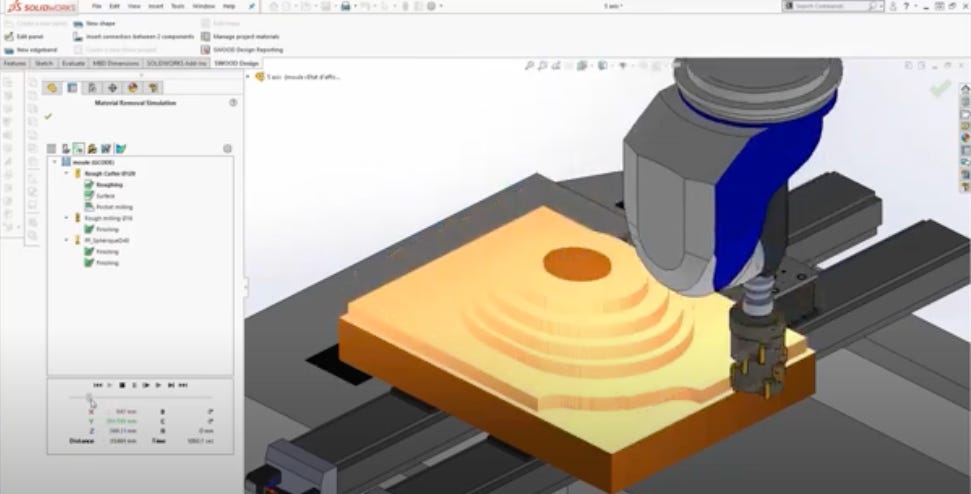
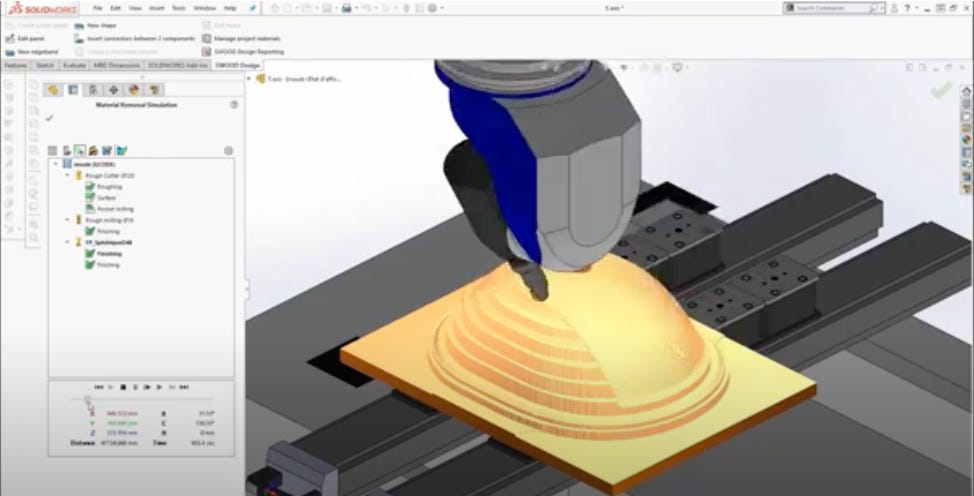
For a lot of reasons, I decided to build my simulation using polygonal representations for the robot, tool, stock, etc. For each step of the visualization, I would create a new form by taking the tool at time = 0, and sweeping it through the path defined by the G-code until the current step of the simulation, twisting and turning along the way, as needed. And then I’d do a boolean subtraction of the swept tool from the current state of the stock. Again, all in polygon space.
For example, for a cylindrical tool and a linear path, the new swept form I would create would look like a rectangular solid with half-cylinder end caps. Subtracting a rectangular solid with rounded end caps from a block of simulated material is pretty straight forward stuff, and my simulation was cooking along beautifully. Then I got cocky. Driving the tool along a six degree of freedom path (three translational, three rotational axes) resulted in the simulated stock suddenly exploding into polygonal shards all over the display. Something didn’t make sense.

Candidly, I don’t remember the exact numerical condition that created all of the degenerate polygons that ruined my simulation, but I remember the cause clearly: the floating point fidelity of the CPU. Somehow, the boolean operation between the zigging and zagging and rotating tool and the simulated stock had resulted in a polygonal model that ended up with a degenerate side. The standard 32 bit floating point representation wasn’t enough to accurately represent the distance between one vertex on the (translated, rotated) tool polygon and a corresponding vertex on the stock polygon.
In my decades of experience in the software industry, I can think of only two times where the floating point limits of the hardware materially impacted the results produced by our software. One was this material removal example (solved by forcing all polygon vertices to snap to a fixed unit 3D grid), and the other had to do with the standard matrix algebra libraries used on the old Silicon Graphics machines in the mid-90’s. For the high-performance 4x4 matrix transformations required for on-screen animations of complex 3D geometries, the SGI libraries were hardwired to use short float (32 bit) representations, and we were trying to leverage the libraries in some calculations involving long float (64 bit) numbers. The resulting loss in fidelity created side effects that took a long time to diagnose.
Anyway, my point here (and I do have one) is that, even if the model is supposed to be deterministic, computer hardware does have limits that can cause unexpected results for certain edge cases. In the case of LLMs, the scale of computation is profound: you’re essentially doing an optimization calculation in several hundred thousand dimensional space for every token you add to a generated answer. It’s not at all implausible to assume there will be some variability in results due to the limitations of computational hardware. I have seen acknowledgement of these concerns in multiple places (e.g. here, here, here, with the caveat that nondeterminism is sometimes conflated with the "perception of nondeterminism"), but I have yet to see the impact quantified.
Of Course, You Can Make it Stochastic
The outputs of a neural network can be, and often are, post-processed to make the results appear stochastic (e.g. see the Temperature parameter in popular LLMs), and, candidly, to make ChatBots appear more "human." If you go to chat.openai.com, you're interacting with an LLM that defaults to using a non-zero Temperature parameter. Oversimplifying, but a zero Temperature will always select the “best” (according to the model) next word, and a larger Temperature will allow the model to vary more and more from the “best” answer, sometimes select the second, third, … , fifth “best” next word. Since LLMs are autoregressive (the output for one stage becomes part of the input to the next), results for a given prompt quickly diverge when the Temperature value is non-zero.
Stochastic behavior can also arise if the model is using a mixture of experts approach, where the results from multiple LLMs are combined to create a single result for users. Depending on how the multiple results are combined, stochastic variability can appear in the output (but each LLM Expert is still deterministic).
“It’s really just statistical autocomplete …”
Full disclosure, I actually said those exact words to my mother as she was trying to add AI-mediated doom to her list of things to worry about. And, the chatbots we see now are, kinda, sorta, statistical things. So practically speaking, I don’t think it’s at all unreasonable to think of chatbots that way out in the normal world.

However … for building commercial solutions based on LLMs, I find it much more appropriate (and accurate) to think about them in terms of complexity. Statistics can be part of a solution to manage this profound complexity, but statistical variation isn’t the core issue.
It’s Complex
So, when it comes to understanding how to leverage these technologies for commercial solutions where (apparent, stochastic) variation is unacceptable, dialing down the Temperature parameter is often not going to be enough, taking aspiring solution providers into a fascinating and terrifying world of decision making in incomprehensibly high-dimensional latent spaces, chaos theory, and the physical limitations of computational hardware.
Ultimately, it seems to me that the real challenge is dimensionality reduction: going from the impossibly complex, several hundred thousand dimensional latent space of a foundational LLM to a much smaller, more manageable conceptual space that corresponds to crisp, repeatable, and dependable decision making in the solution domain of interest. Think of it this way, somehow, you have to map all of the concepts inferred from the data used to train the foundational model (all of the concepts documented on the public internet, for example), down to a much smaller set, e.g. the risk is High, Medium, or Low.
As per previous posts, it all comes back to the data you can use to augment these foundational models (if you can’t train your own, that is). Can you identify a compelling corpus of information that, when compiled down to a vector embedding for your LLM of choice, results in generated content that allows your solution to reliably do [what you need it to] in your domain of interest?
To be clear, I am speculating, because the answer to the question around the variability of LLM output is exactly the secret sauce that will enable the next generation of solutions, and people aren’t exactly eager to give away the crown jewels. But, for me at least, the keyword of the day is Complex, not Stochastic.
Kurt Skifstad has 30 years’ experience founding and running venture-backed software companies, a PhD in AI, and a fondness for run-on sentences
Your point is spot on, Kurt. In my consulting work, I'm using LLMs frequently but have concluded that while I provide a prompt, it's merely giving me a prompt back. Then it's up to this human to think about what to use or approach to take.